Arquitetura de Web Scraping em Rust para Extração de Dados Escalável

Adélia Cruz
Neural Network Developer
TL;DR
- O web scraping em Rust funciona melhor quando buscar, analisar, renderizar e armazenar são separados em camadas distintas.
reqwestescrapercobrem muitos alvos estáticos com menor custo de recursos e manutenção mais limpa.- O scraping assíncrono com Tokio melhora a taxa de transferência para trabalhos limitados por I/O, mas ainda precisa de limites de taxa, repetições e controle de fila.
- O scraping com navegador headless deve ser um fallback seletivo para páginas renderizadas com JavaScript, em vez do caminho padrão.
- Proteção contra bots, rotação de proxies e eventos CAPTCHA devem ser tratados com políticas claras e design de automação compatível.
- Para fluxos de automação legítimos que atendem a uma necessidade real de negócios, CapSolver pode se encaixar em uma camada de fallback estreita seguindo seu fluxo de API oficial.
O web scraping em Rust é mais eficaz quando projetado como uma arquitetura, não como um único script. Este artigo é para engenheiros, equipes de dados e operadores técnicos que precisam de extração confiável em larga escala. A principal conclusão vem primeiro: os melhores sistemas de web scraping em Rust mantêm o caminho rápido simples com reqwest e scraper, adicionando scraping assíncrono, scraping com navegador headless, rotação de proxies e tratamento de desafios apenas quando o alvo realmente os requer. Essa estrutura reduz custos, melhora a estabilidade e torna os pipelines de longa duração mais fáceis de observar.
Visão Geral do Web Scraping em Rust
O web scraping em Rust é uma escolha sólida para grandes tarefas de extração, pois combina segurança de memória com desempenho previsível. Essas qualidades importam quando um trabalhador pode processar milhares de páginas, analisar marcação instável e gravar registros normalizados por horas.
A maioria dos artigos nos resultados de busca explica como buscar uma página e analisar um seletor. Esse material é útil, mas raramente responde à pergunta mais difícil. Como deve ser a arquitetura completa de web scraping em Rust quando você precisa de resiliência, observabilidade e espaço para escalar?
Um design de produção geralmente precisa de uma camada de busca HTTP, uma camada de análise, uma ramificação de renderização para páginas JavaScript, uma camada de armazenamento e uma camada operacional para repetições, métricas e ritmo de solicitação. A ordem correta também é importante. Comece pelo caminho mais barato primeiro. Busque HTML bruto. Analise apenas os campos que você precisa. Escalone para scraping com navegador headless apenas quando o HTML do servidor não contiver os dados alvo. Adicione rotação de proxies apenas quando a distribuição de tráfego ou acesso regional for necessária. Adicione tratamento de CAPTCHA apenas quando um fluxo de automação compatível tiver uma razão válida para continuar.
Para equipes que planejam esses limites, raspagem e coleta de web ajuda a esclarecer o escopo, e como extrair dados estruturados é uma leitura útil antes do mapeamento de campos.
Bibliotecas Principais para Raspagem em Rust
O web scraping em Rust geralmente começa com três blocos de construção: reqwest, scraper e Tokio. A documentação oficial reqwest descreve o reqwest como um cliente HTTP de nível superior com suporte assíncrono, cookies, redirecionamentos, TLS e suporte a proxies. Isso o torna uma camada de transporte prática para web scraping em Rust.
A documentação oficial tutorial assíncrono do Tokio explica por que futuros e o modelo de executor se encaixam em trabalhos de I/O de alta concorrência. Isso importa porque o web scraping em Rust passa a maior parte do tempo esperando servidores remotos, em vez de queimar CPU com cálculos locais.
Requisições HTTP com reqwest
reqwest deve estar na camada de transporte. Reutilize um cliente único por trabalhador ou grupo de trabalhadores. Isso mantém o agrupamento de conexões eficaz e dá a você um único lugar para definir cabeçalhos, timeouts, cookies e política de proxies.
rust
use reqwest::Client;
use scraper::{Html, Selector};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let client = Client::builder()
.user_agent("Mozilla/5.0")
.build()?;
let html = client
.get("https://example.com")
.send()
.await?
.error_for_status()?
.text()
.await?;
let document = Html::parse_document(&html);
let card = Selector::parse("article")?;
for node in document.select(&card) {
println!("{}", node.text().collect::<Vec<_>>().join(" "));
}
Ok(())
}Este padrão mantém o web scraping em Rust eficiente em páginas estáticas. Também torna o tratamento de erros mais fácil de padronizar. Verificações de status, orçamentos de repetição e logs estruturados podem todos viver ao redor da camada de solicitação em vez de serem misturados no código do analisador.
Análise de HTML com scraper
scraper pertence a uma camada de análise que permanece pequena e testável. Não misture seletores com lógica de rede se você espera que os modelos mudem. Um analisador forte aceita HTML bruto e retorna registros tipados, registros parciais ou um erro claro de extração.
Essa separação importa porque a mudança de seletores é comum. Classes mudam. Texto se move para atributos. Nós decorativos aparecem entre elementos alvo. Na raspagem em Rust, a isolamento do analisador torna esses problemas visíveis em testes antes que todo o pipeline comece a gravar dados incompletos.
Arquitetura de Scraping Assíncrono
O scraping assíncrono é uma das principais razões pelas quais o web scraping em Rust pode escalar bem em infraestrutura modesta. O runtime não faz os sites responderem mais rápido. Ele torna os trabalhadores mais eficientes enquanto muitas solicitações estão esperando por rede ou resposta de origem.
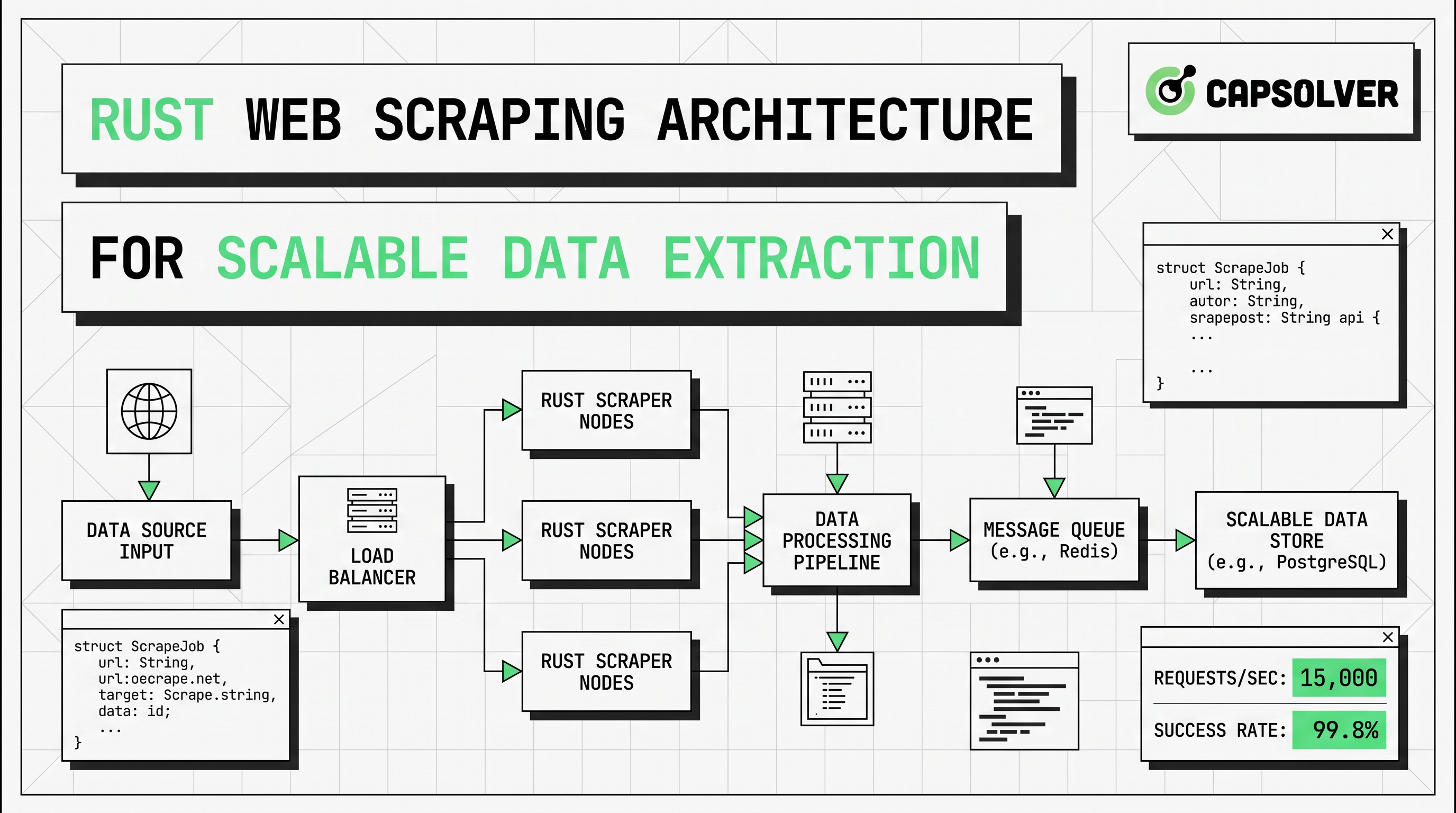
Um pipeline de web scraping em Rust escalável geralmente segue a estrutura abaixo.
| Camada | Papel | Padrão do Rust | Risco principal |
|---|---|---|---|
| Scheduler | Escolhe URLs e prioridade | fila ou canais | tráfego em surto |
| Fetcher | Envia solicitações HTTP | reqwest::Client |
403, 429, timeout |
| Parser | Extrai campos | seletores scraper |
mudança de modelo |
| Renderer | Carrega páginas JS | raspagem com navegador headless | custo de CPU e memória |
| Camada de desafio | Trata eventos CAPTCHA permitidos | fallback do CapSolver | tipo de tarefa incorreto |
| Armazenamento | Grava saída normalizada | JSON, CSV, DB | incompatibilidade de esquema |
| Observabilidade | Rastreia saúde e qualidade | logs, rastreamento, métricas | perda de dados silenciosa |
A regra de design principal é a escalada seletiva. Comece cada alvo no caminho de baixo custo. Se o HTML retornado já contiver os dados, fique com reqwest e scraper. Se os campos só aparecerem após a hidratação, renderização do cliente ou eventos do navegador, direcione apenas esse tipo de página para raspagem com navegador headless. Se controles de proteção contra bots ou verificações CAPTCHA aparecerem dentro de um fluxo aprovado, direcione apenas esses eventos para uma pequena ramificação de fallback.
É aqui que muitos sistemas se tornam desperdiçadores. As equipes usam automação de navegador para cada solicitação por padrão. Isso aumenta os custos, reduz a concorrência e torna os falhas mais difíceis de classificar. O relatório do Estado do JavaScript do HTTP Archive mostra que páginas modernas ainda dependem fortemente de JavaScript, com um tamanho médio de transferência de JavaScript de 803,3 KB e 23 solicitações de script externas na visualização do relatório selecionado. Isso explica por que alguns alvos precisam de renderização, mas não justifica o uso de navegadores para cada página.
Tratando Páginas Renderizadas com JavaScript
A raspagem com navegador headless é necessária quando os dados são criados após a resposta HTML inicial. Sinais comuns incluem HTML do servidor vazio, conteúdo injetado após a hidratação, listas com rolagem infinita ou páginas que revelam campos apenas após interação do usuário.
O web scraping em Rust deve tratar a renderização do navegador como uma ramificação separada, em vez de um padrão universal. Use-o para grids de produtos que se preenchem após solicitações do cliente, dashboards renderizados no navegador ou interfaces onde o conteúdo principal está oculto atrás de cliques e lógica de rolagem. Mantenha o grupo de navegadores pequeno e isole-o dos seus trabalhadores HTTP assíncronos principais.
Uma regra prática prática é simples. Se os dados estiverem presentes no HTML bruto, fique com reqwest e scraper. Se os campos aparecerem apenas após a execução do JavaScript, mova esse caminho para a raspagem com navegador headless. Se o mesmo alvo também aplicar controles de proteção contra bots, revise a política de rede, comportamento do navegador e requisitos de fallback juntos em vez de corrigi-los um por um.
Para leitura interna relacionada, automação de navegador para desenvolvedores e automatizando a resolução de CAPTCHA em navegadores headless se encaixam naturalmente nesse modelo de camadas.
CAPTCHA e Limitações de Scraping
O web scraping em Rust sempre tem limites. Alguns são técnicos. Outros são legais ou operacionais. O lado técnico inclui reputação de IP, tratamento de sessão, verificação de impressão digital do navegador, APIs ocultas e proteção de bots em camadas. O lado operacional inclui ritmo de solicitação, orçamento de erros e impacto do tráfego no site alvo.
É por isso que a conformidade deve ser construída na arquitetura. A guia do Google Search Central sobre robots.txt explica que robots.txt é principalmente usado para gerenciar o tráfego de crawlers e evitar sobrecarregar sites. Esse ponto importa para o web scraping em Rust porque um sistema bem projetado não está apenas tentando extrair dados. Ele também está tentando controlar a carga, reduzir solicitações desnecessárias e manter o comportamento de coleta razoável.
Quando fluxos de automação legítimos encontram etapas CAPTCHA, CapSolver é relevante como um serviço de fallback focado. A abordagem mais segura é seguir a documentação oficial em vez de inventar formatos de solicitação personalizados. A documentação do CapSolver createTask mostra o padrão de corpo da solicitação padrão abaixo.
json
POST https://api.capsolver.com/createTask
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey":"SUA_CHAVE_DE_CLIENTE",
"appId": "ID_DA_APLICACAO",
"task": {
"type":"ImageToTextTask",
"body":"IMAGEM_EM_BASE64"
}
}O mesmo fluxo oficial retorna um taskId para tarefas assíncronas, que deve então ser verificado por meio de getTaskResult. Em um sistema de web scraping em Rust escalável, esse lógica de desafio deve permanecer fora do caminho padrão de busca e análise para que solicitações normais permaneçam rápidas e fáceis de monitorar.
Resgate seu código promocional do CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código promocional CAP26 ao recarregar sua conta do CapSolver para obter um bônus adicional de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
Escalando Raspadores em Rust para Coleta de Dados em Grande Escala
Escalar o web scraping em Rust é principalmente sobre controle, não sobre volume de código. A arquitetura deve impor concorrência por domínio, teto de repetições, orçamento de timeout e validação de saída. Sem esses controles, trabalhadores mais rápidos simplesmente criam falhas mais rápidas.
A rotação de proxies pertence à camada de transporte, não à camada de análise. Use-a quando as solicitações precisarem de distribuição entre endereços IP para equilíbrio de taxa, acesso regional ou isolamento de carga. Mantenha a política específica. Roteie por domínio, classe de endpoint ou tipo de carga. Evite mudanças aleatórias de proxy que quebrem a continuidade da sessão e adicionem ruído ao depuração.
Também é aqui que recursos internos de suporte se tornam úteis. Melhores serviços de proxies podem ajudar a avaliar a estratégia de rede, enquanto legalidade do web scraping é um ponto de verificação interno útil antes de expandir o volume de coleta.
Os sistemas mais fortes de web scraping em Rust também medem a qualidade da extração diretamente. Rastreie taxa de sucesso, taxa de campos vazios, desvio de seletores, taxa de renderização, latência média de busca e custo por registro bem-sucedido. Essas métricas mostram quando um caminho HTML estático ainda é suficiente e quando a raspagem com navegador headless, rotação de proxies ou tratamento de desafios está se tornando muito caro.
Resumo da Comparação
| Abordagem | Caso de uso ideal | Perfil de custo | Perfil de confiabilidade | Observações |
|---|---|---|---|---|
reqwest + scraper |
páginas estáticas ou levemente dinâmicas | baixo | alto quando seletores são estáveis | melhor padrão para web scraping em Rust |
| Scraping assíncrono com trabalhadores Tokio | muitas URLs limitadas por I/O | baixo a médio | alto com limites de taxa | melhora a taxa de transferência, não a qualidade do analisador |
| Scraping com navegador headless | páginas renderizadas com JavaScript | alto | médio | isole-o em um pequeno grupo |
| Rotação de proxies | controle de taxa distribuído e acesso geográfico | médio | médio | útil quando a identidade do tráfego importa |
| Fallback do CapSolver | eventos CAPTCHA permitidos em fluxos de automação | baseado em evento | médio a alto | mantenha a implementação alinhada com a documentação oficial |
Conclusão
O web scraping em Rust escala quando a arquitetura permanece seletiva. Use reqwest e scraper para o caminho rápido. Adicione scraping assíncrono quando você precisar de maior taxa de transferência em trabalhos limitados por rede. Reserve o scraping com navegador headless para páginas que realmente precisem de renderização. Mantenha a rotação de proxies e o tratamento de desafios como camadas de fallback controladas. Essa design mantém custos menores, melhora a observabilidade e torna a manutenção do analisador muito mais fácil.
Se seu pipeline atual roteia cada página por um navegador, a melhoria mais limpa geralmente é uma divisão de caminho. Mova os alvos estáticos de volta para HTTP simples. Mantenha páginas JavaScript em uma pequena ramificação de renderização. Mantenha a lógica de desafio isolada. Essa mudança sozinha muitas vezes melhora tanto a confiabilidade quanto a economia unitária.
Perguntas Frequentes
O web scraping em Rust é melhor que o Python para grandes tarefas?
O web scraping em Rust é frequentemente uma escolha sólida quando estabilidade de longo prazo, concorrência e segurança de memória são mais importantes. O Python ainda tem um ecossistema mais amplo de raspagem, mas o Rust é atraente quando a eficiência do trabalhador e o desempenho previsível são as prioridades principais.
Quando devo mudar de reqwest para scraping com navegador headless?
Mude apenas quando o HTML do servidor não contiver os campos que você precisa. Se os dados alvo aparecerem após a hidratação, eventos do cliente ou solicitações de API atrasadas, o scraping com navegador headless se torna justificado.
Como o scraping assíncrono ajuda no Rust?
O scraping assíncrono ajuda o web scraping em Rust a lidar com muitas solicitações em espera com menos recursos desperdiçados. Melhora a taxa de transferência para trabalhos limitados por I/O, mas ainda requer limites de taxa, lógica de repetição e testes do analisador.
Sempre preciso de rotação de proxies?
Não. Muitos trabalhos funcionam bem sem isso. A rotação de proxy importa quando você precisa de acesso regional, distribuição de tráfego por domínio ou menor concentração de uma única faixa de IP.
Como devo tratar as páginas CAPTCHA em um fluxo de trabalho compatível?
Mantenha o tratamento de CAPTCHA estreito, documentado e separado do caminho normal de coleta. Se um fluxo de trabalho de automação legítimo exigir isso, use o fluxo de tarefas oficial do CapSolver e mantenha a implementação consistente com a documentação publicada.
Ver mais
web scrapingApr 08, 2026
Selenium vs Puppeteer para Resolução de CAPTCHA: Comparação de Desempenho e Caso de Uso
Compare o Selenium vs Puppeteer para resolver CAPTCHA. Descubra benchmarks de desempenho, notas de estabilidade e como integrar o CapSolver para o máximo de sucesso.

web scrapingFeb 10, 2026
Dados como Serviço (DaaS): O que é e por que importa em 2026
Entenda Dados como Serviço (DaaS) em 2026. Descubra seus benefícios, casos de uso e como transforma os negócios com visões em tempo real e escalabilidade.
